Freewheeling Apps are a durable substrate
for the future of software.
Easy to download. Easy to run. Easy to modify. Easy to share.
Free and open source. I'm not trying to make money from them, only meaning. I'm beholden to nobody. No dark patterns, ever. I'll never sell them to someone else; there's nothing to sell.
All apps reward curiosity. I care about the experience of making changes to them as much as the experience of using them. You can often look inside the app you're running and modify it with the press of a button, without needing additional software.
Each app quickly stabilizes, and then seldom updates. Because timeless software is safer and more trustworthy (it can't change its mind). Definitely no auto-updates. I think I might be able to get to 50 years without an update. Join me on that voyage!
Individual apps stay simple; apps spawn forks and remixes rather than grow complex.
All the apps
A family tree, with forks indented below their parents. If multiple forks need a change, it's often convenient for me to make the change as high up (unindented) in this tree as possible.
lines.love: The original plain-text editor you can draw line-drawings in.
lines-and-links: A few lines modified to support clickable links. If a word surrounded by whitespace corresponds to a filename it gets an underline and becomes clickable. Now pulled into some of my other apps.
lines-cjk.love: A place to support CJK languages. Currently only has a font change, because I don't know any of these languages. If you'd like to help, please get in touch.
lines-mobile.love: lines.love tested for mobile devices. Adds a file picker where the original switches to new files when you drop their icons on the window.
etch.love: an ephemeral slate you can write and draw shapes on, then export to html+SVG with the press of a button.
pensieve.love: The app I use for all my note-taking. Manages 800MB of notes over 20 years.
techmeet.love: fork of pensieve.love for a specific community. If you'd like one for your community, please get in touch.
capture.love: A secondary tool for pensieve.love. Sometimes I just want to capture a note on a blank slate without getting distracted by the giant dashboard of all my notes. But what I capture here still becomes available in pensieve.love.
lines2.love: A new version of lines.love with radically rearchitected internals. Among other things, it enables structured editors to be more easily created. But it's also smaller, faster and more robust.
text2.love: lines2.love with all the line-drawing support ripped out. Frees up complexity I can use to take it in new directions.
view2.love: text2.love with all the editing support ripped out.
fractions.love: A structured editor for fractions rendered vertically (with a horizontal divider rather than a slash as we've gotten accustomed on computers). Demonstrates the sorts of things lines2.love makes much easier to accomplish.
notebook.love: A rudimentary computational notebook where you can write prose containing named blanks, and perform arithmetic in indented lines that fills in named blanks.
highlight.love: A viewer for simple styled text with configurable colors.
curio1.love: A little toy exploration of a tiny state space of 8 similar programs. See each one running, look at its source code, compare its source code with “nearby” programs.
tabs.love: Prepend 3 dashes to any line in a text file to turn it into a bookmark ‘tab’ in the right margin that you can click on to jump to it. This app embodies the kind of interaction I live for: somebody came up with the idea for it online, and I was inspired to build it for them. If you ever think of an idea and wish you could build it, please get in touch.
doodle2.love: An experiment in drawing doodles alongside text. Doodles are attached to a specific character and move/delete with it.
attributes.love: An experiment in maintaining ranged attributes as in Emacs.
template-live-editor2: Template repository for a new approach to code editing. Forks of this app can be edited live as they run using the driver.love app below.
carousel2.love: Lua Carousel, a small environment for writing small, throwaway programs on phone or computer.
text.love: lines.love with all the line-drawing support ripped out. Frees up complexity I can use to take it in new directions.
view.love: text.love with all the editing support ripped out.
links.love: A few lines modified to support clickable links. If a word surrounded by whitespace corresponds to a filename it gets an underline and becomes clickable. Compare lines-and-links above; this one just doesn't have drawings.
pong.love: An experiment in code editing. A game of Pong whose source code you can edit any time by pressing ctrl+e. Now this support has been pulled into many of my apps.
template-live-editor: Older template repository for building live-editable apps. Fork any new apps from template-live-editor2 above. But all the forks below continue to work and can be live-edited. The protocol with driver.love has not changed.
sum-grid.love: Little app for helping first-graders practice addition by solving magic square problems. I made this when my kids ran out of such problems in their textbook and were hungry for more.
carousel.love: Lua Carousel, a small environment for writing small, throwaway programs on phone or computer.
carousel-cards.love: An easy series of puzzles to trick yourself into learning programming. At every point you have a fully programmable environment available if the muse strikes and you want to forget the puzzles and build something new.
template-carousel-mobile: Template repository for apps that can run and be modified on mobile devices as well as computers.
sokoban.love: A client for Sokoban. Play 500+ puzzles on phone, tablet or computer. If you want to skip to a level far away, edit the source code. I believe it is possible to create apps with good UX that require editing their source code for some tasks. Tell me how far I am from demonstrating that.
broadsheet.love: A text viewer that wraps lines at a readable length, switching to multiple columns as it finds space.
spell-cards.love: Rudimentary flashcard app for helping set spelling exercises for schoolchildren based on voice recordings of words.
crosstable.love: Little tool for managing tournament cross-tables. Automates the drudgery of sorting rows and columns at once.
luaML.love: A template repository for rendering a very simple markup “language”. There's no new syntax, you just work with Lua table literals.
snap.love: A tool for drawing boxes and arrows. Probably my single most used app.
~alex27/snap.love: A fork for someone else with some custom features. If you'd like a custom fork of any app for yourself, please get in touch. My apps provide source code and are easy to modify, but it doesn't have to be you modifying them. You just have the option to make changes to them any time in the future. If you have ideas, I'd love to bring them to life.
table.html: A table you can edit on your browser. Though you still need to adjust rows/columns outside the browser.
tz.html: A timezone converter with minimal interactivity, that you can share around confident that everyone is seeing exactly the same thing you are.
annotations: An environment where you can paste in some text, then annotate it on a second column and save your annotations locally alongside the text.
I'll also include here an “approll” of simple offline-friendly html apps by others that I admire and have been influenced by:
· note by Cristóbal Sciutto Rodríguez, the seed for all my html projects so far.
· Yon, m15o's text editing environment inspired by the Plan9 Acme editor.
· ink n switch, Eli Mellen's text editor that you can also doodle on.
· Tom Larkworthy has been doing some fascinating work to make Observable offline-friendly.
Coming soon: networking. Freewheeling Apps will become much more useful when you can use them to get your data out of other silos service providers.
It started, as it often does, with my kids. They got curious about a chess variant called Monster chess. But none of the websites out there have an implementation of it. So I set out to build one. In Lua Carousel, of course, my cross-platform app for editing and running little Lua scripts on phone, tablet or computer.
Now, like all the best chess variants, this one uses all the rules of chess, just with one crucial, minimal tweak. So to implement Monster chess I had to first implement chess. Which I did (and not for the first time). But by the time I'd implemented all the legal moves, castling, en passant, pawn promotion, forbidden moving into check -- I was at 500+ lines of code. At that scale of program, Carousel's janky scrollbars get too thin for my fat fingers to acquire on the phone. Carousel's only nice up to 100-150 lines.
So I switched to my template repository for standalone apps using the Carousel UI. I've done this before, most notably with my Sokoban client which you can edit the source code for right on your phone. Indeed, editing the source code is the expected way to skip 10 or 60 levels. On some level everything I do stems from the desire to believe that editing source code can be a nice user experience.
I soon had a second chessboard app. But it felt like spaghetti. The Carousel template lets me split up a large program into multiple files, but with all the problems of text-based program navigation, and all my bespoke janky tools to boot. You're looking for a specific function. Which file is it in? It's hard to read code you didn't write, and on some level everything I do is an attempt to make it easier. You know, literacy. Computational literacy. The ability to read a novel of code or write an email of code. But we're not at the promised land yet, and meanwhile I have spaghetti nobody should bother with.
So I ripped out all my Carousel stuff and made it just a plain LÖVE app. File size dropped from 128KB to 8KB. So clean! But now it's not easy to modify, particularly on a phone. You have to unpack the zip file, find a text editor, etc. And on some level everything I do is an attempt to keep things easy to modify.
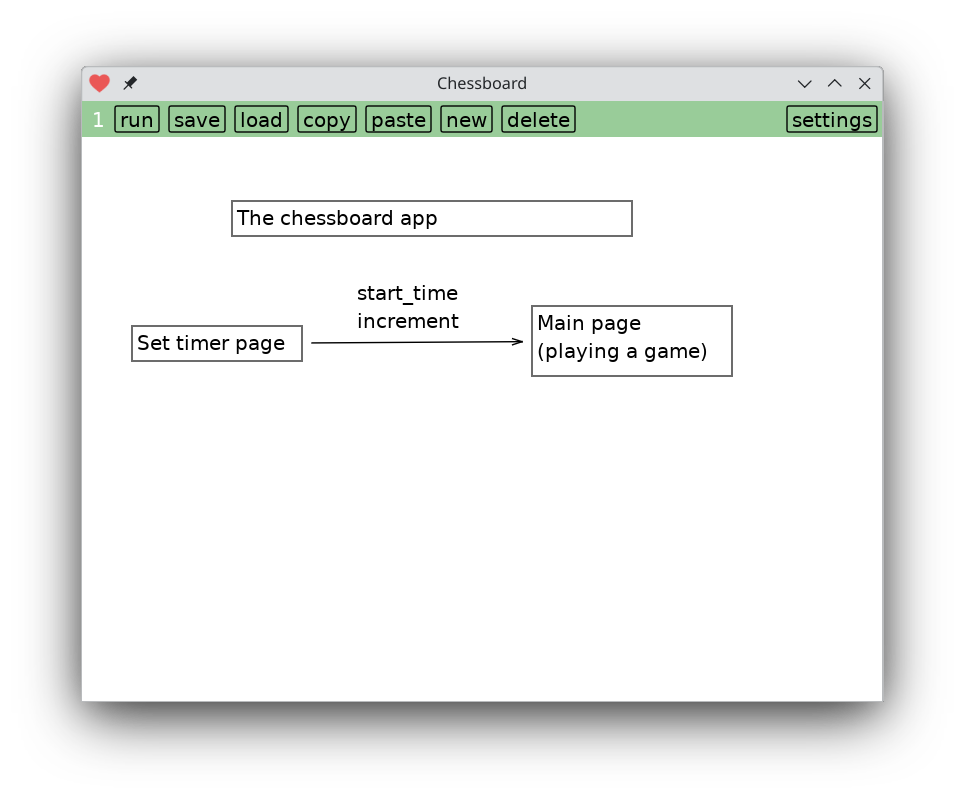
So I spun my wheels for a while. Eventually I remembered that I'm drawing on a graphical canvas, and that I know how to draw box-and-arrow diagrams. What I really need here, I decided, is a way to draw little box-and-arrow diagrams about my program, tapping on boxes to jump to files. It's still extremely janky, but… well, take a look.
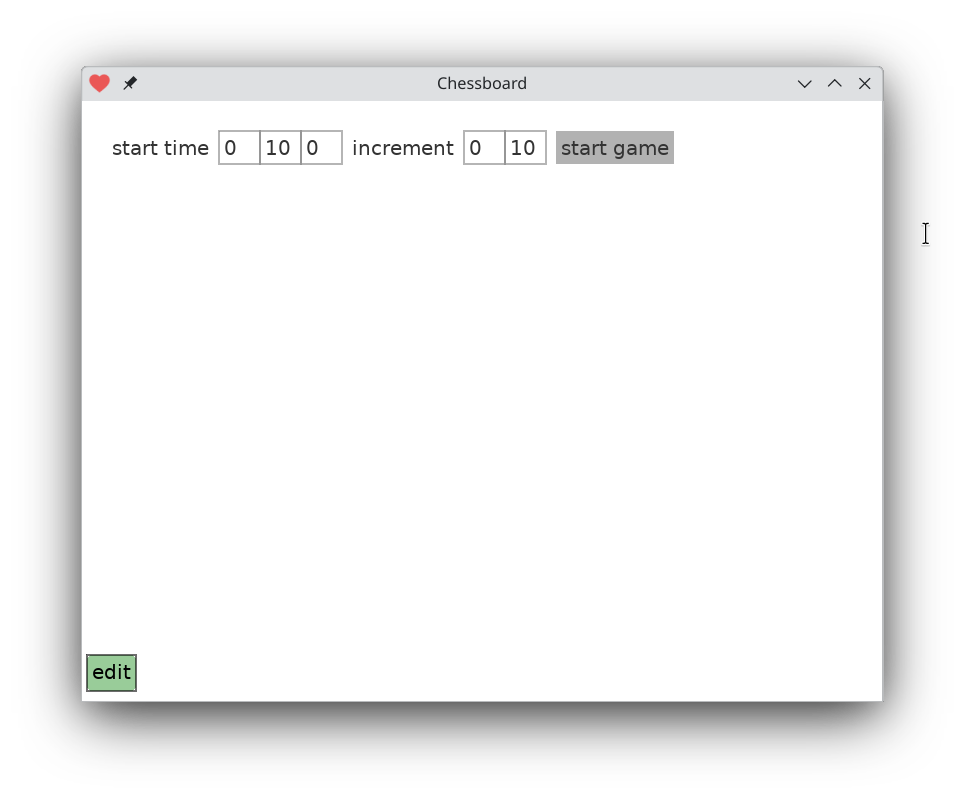
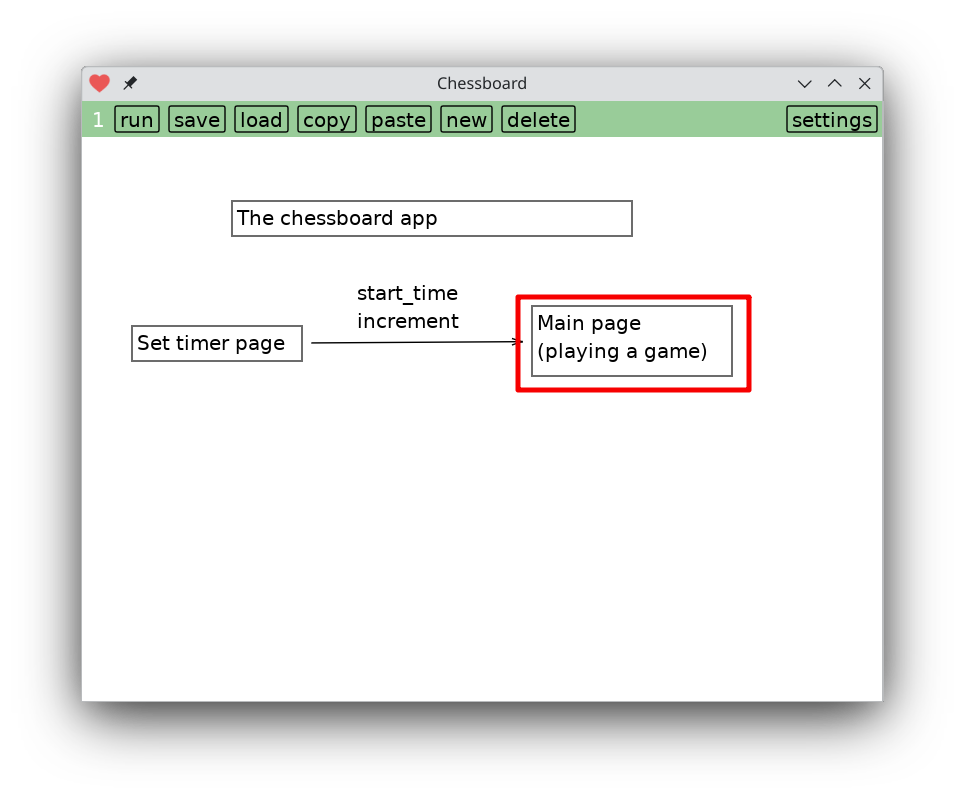
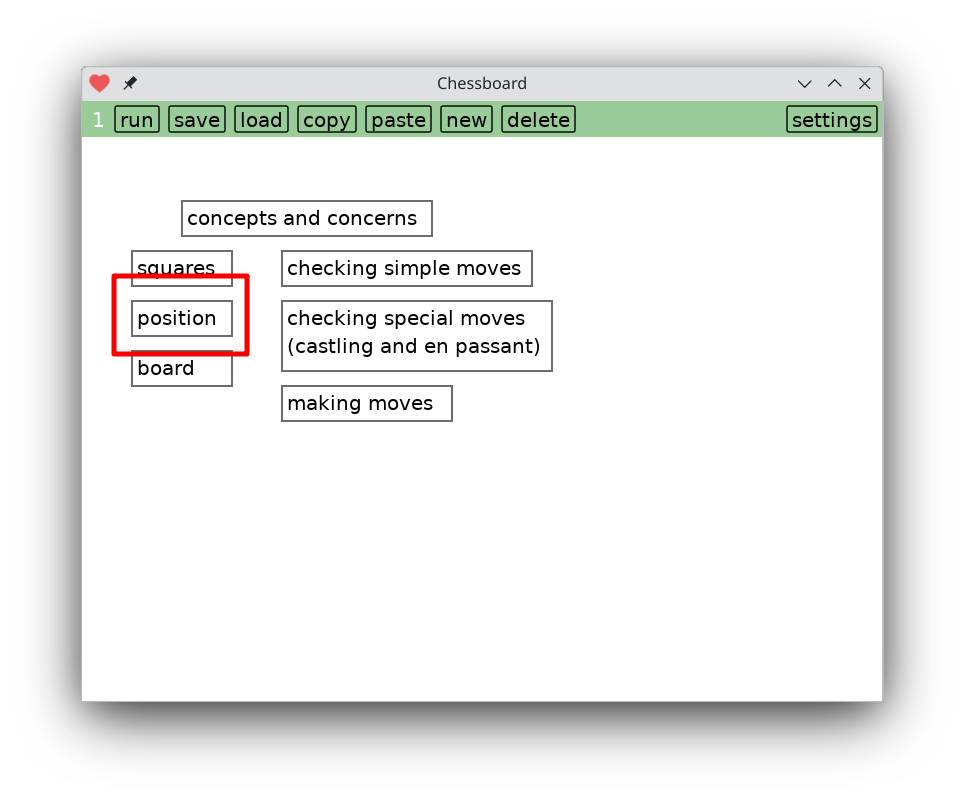
When you run the app you're faced with a screen to select a time control. Edit it to taste, tap ‘submit’ and now you're on the main screen.
That's all there is to using the app. But there's also a button on the bottom left for editing its source code. Tapping on that brings you to this screen.
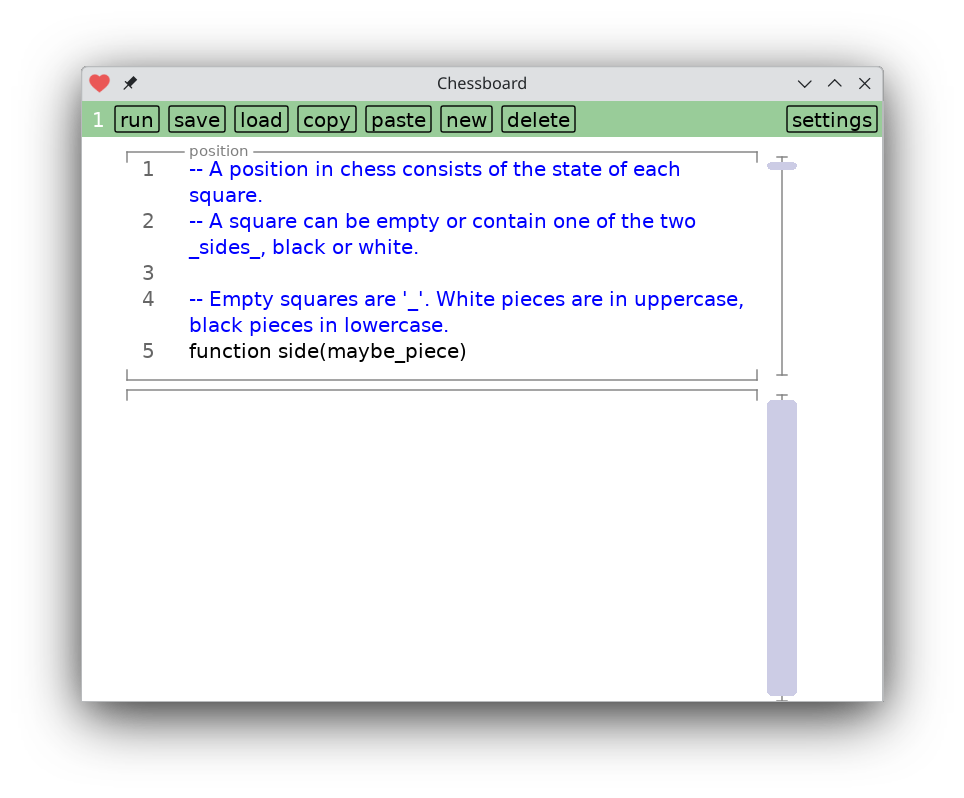
The chessboard app consists of two screens. You start out setting the timer, then you play. There's no way to go back to set the timer. You have to quit and restart the app. Timer page and main game page share two variables: start_time and increment.
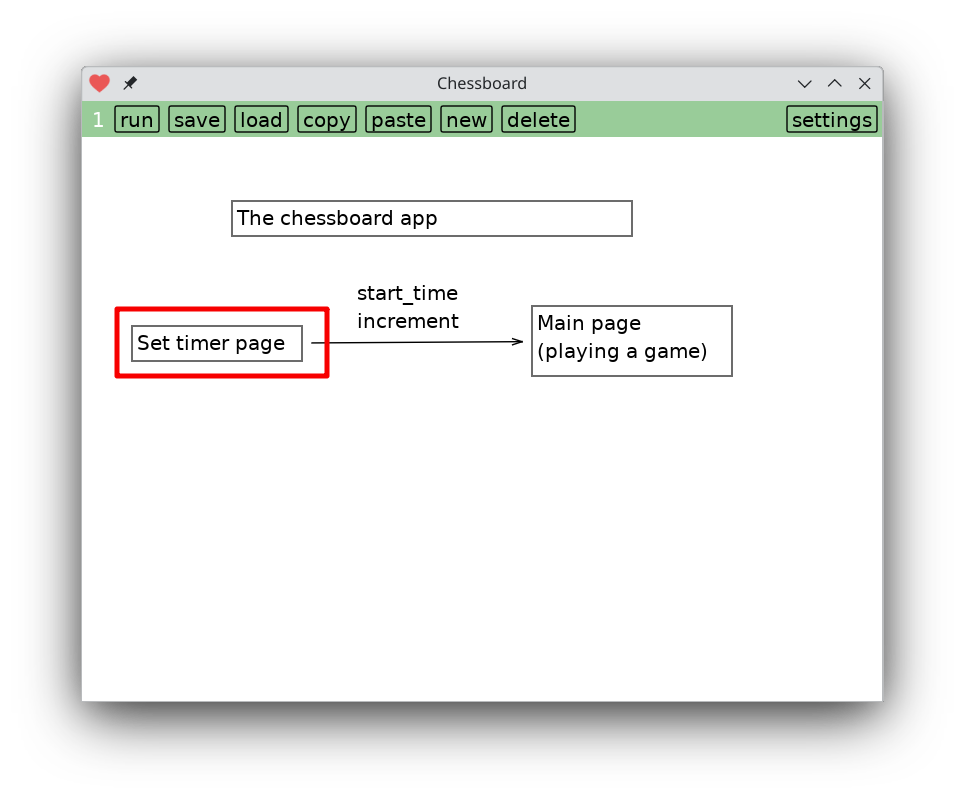
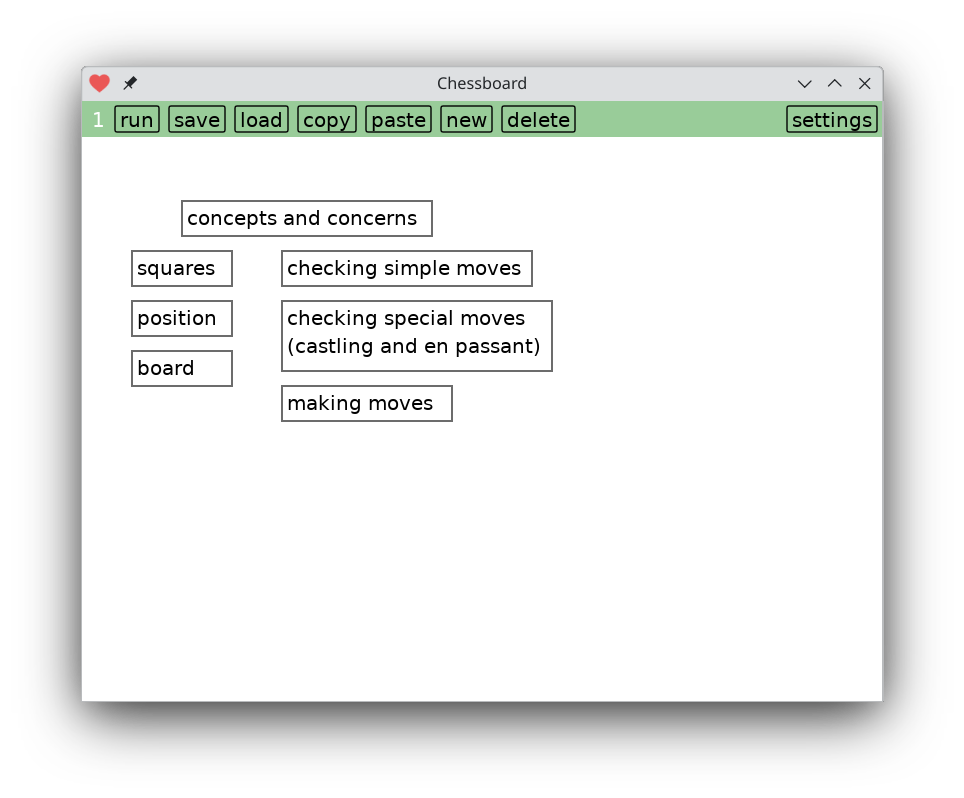
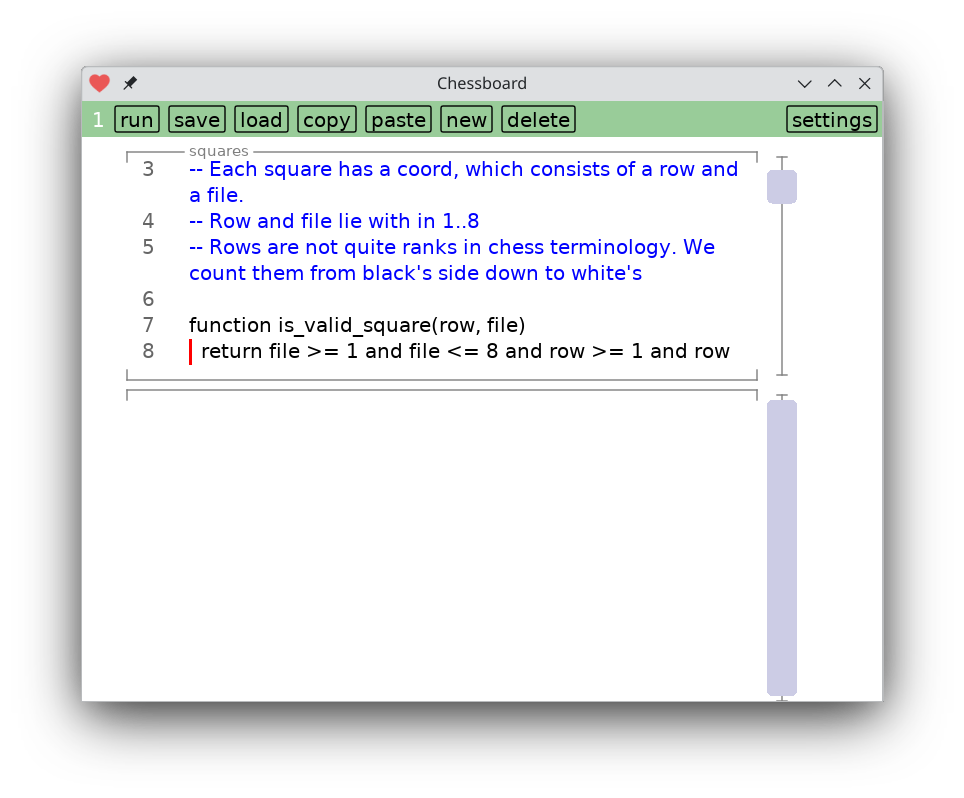
Tapping on the timer page brings you to a screen of code that implements it.
I don't have any ideas to make it easier, so at this point you're stuck reading banal textual code. Hopefully the introductory screen helps find your bearings.
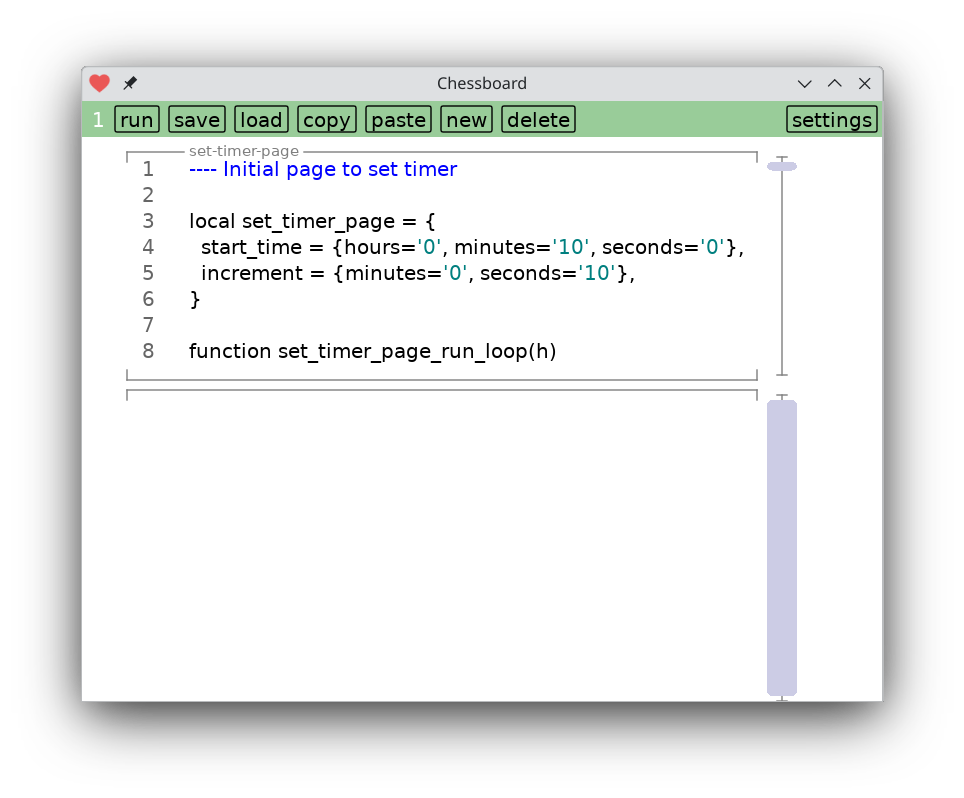
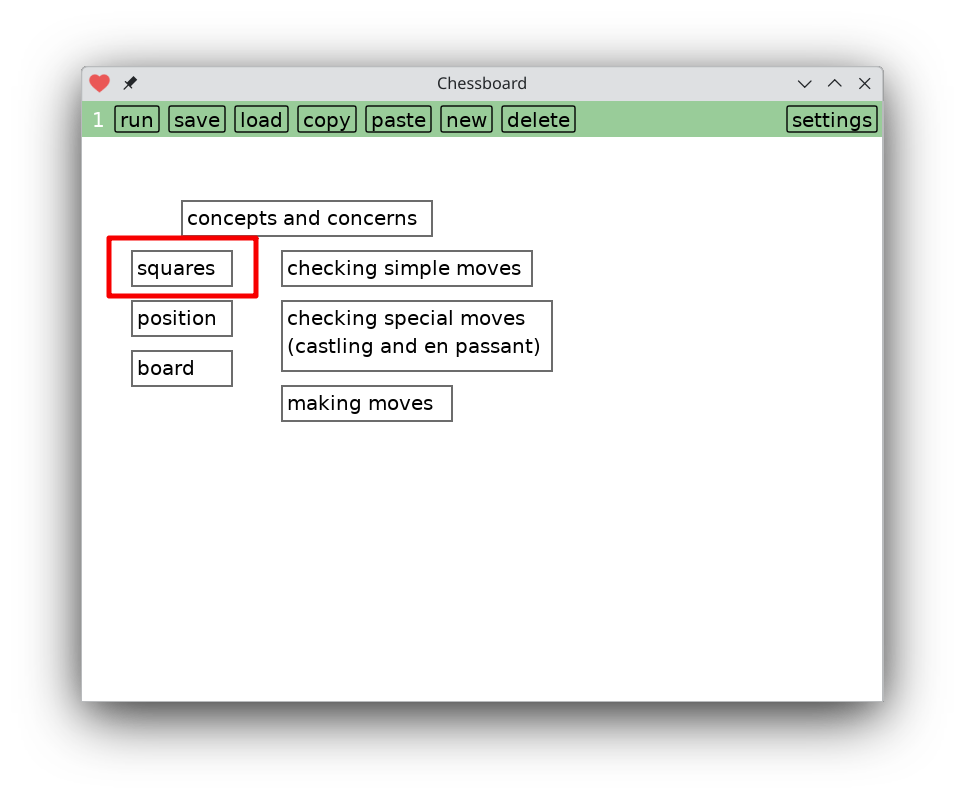
Tapping on the right hand box brings up a second picture, showing some substructure.
Now there are more boxes to tap on, and each of them brings you to a chunk of code to read and digest.
Again, hopefully drawing the eye to certain highlights helps get the reader oriented in a new codebase.
The drawings are just documentation so far. They're redundant with the code, and can go out of date. So I've tried to highlight only the highest level, most permanent features.
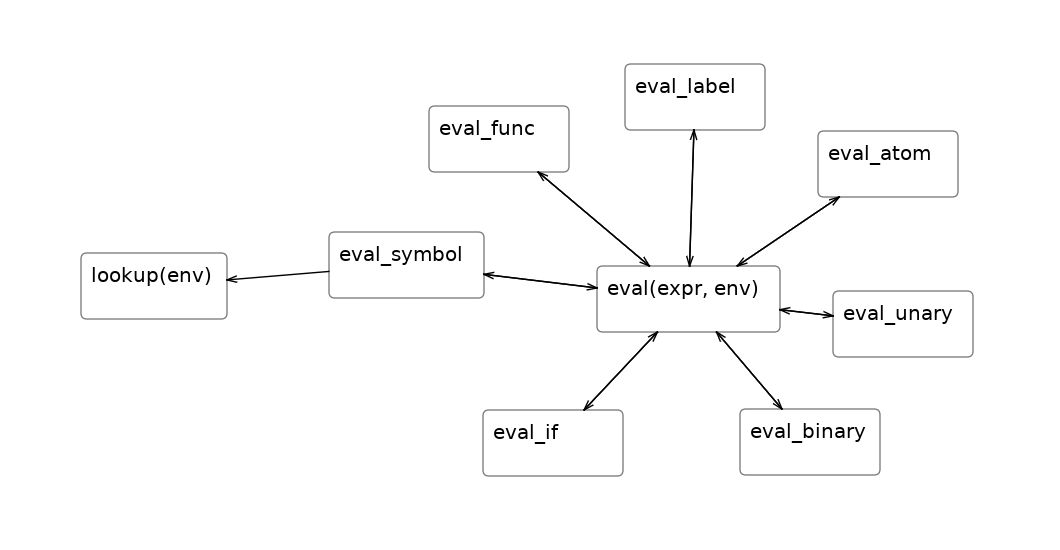
Here's another drawing about a problem I often think about: how to explain a Lisp interpreter to someone seeing it for the first time.
Arrows indicate function calls. A Lisp interpreter is a recursive function. But it can get long and complex, so it's often split into multiple functions. But now the recursion is less obvious, and it can seem intimidating to a newcomer. The word env often shows up everywhere. But as this diagram makes clear, the purpose of env is highly localized. It's only used to look up the value of a variable/symbol. Everywhere else just passes it around to get it where it's needed.
Anyways. This “markup language” (I'm just using Lua literals) for box-and-arrow diagrams and hyperlinks seems like an expressive mechanism for communicating a variety of relationships.
I seem to be alternating between working with html and Lua/LÖVE. In the last few days I've been trying to extract some more timeless tools out of the ad hoc static site I replaced my old Rails website with a couple of years ago. Here's the project. Requires just Lua (any version after 5.1) and nothing else. In particular, it doesn't mess with any Markdown variant, just leaves you to edit raw HTML.
There's 3 tools that you can use independently:
slapping a common template around many files/pages/posts
generating paginated index pages for a list of files/pages/posts
autogenerating a feed of the most recent posts in a list
All 3 tools use a common data source of a) files with some `---` metadata up top and a small number of VARIABLES that get substituted in, and b) index files containing a list of files that constitute a site.
All 3 tools are single-file and so self-contained and easy to move wherever you want, mix and match. For example, my site has two distinct blogs (main site and devlog). I run the first tool once and the others twice each.
I can't quite cut my site over to this, though. Open questions I ran into with my site:
How to style the pagination links. Those bits of html are hard-coded in the generator.
Some of my older blog posts have no titles. Then I want to show the date in the <title> tag, but show no title in the <body> (because I already show the date and it would be redundant). It's unclear how to do that without a whole templating language.
I'm sure there are others. SSGs seem to be one of those things that everyone a unique-snowflake version of. But check it out if you're willing to leave Markdown behind. Using HTML is more accessible than Markdown. For example, it lets you distinguish a couple of key categories of <code>: keyboard shortcuts with <kbd>, references to names in other snippets with <var> and computer output with <samp>. Markdown's backticks can't do that. It doesn't matter if you never share your posts, and it's natural to not want to look at HTML given how monstrous it can get. But HTML also has a lovely core that a lot of civilizational effort went into, and it's sad that layers above don't use all of it. A little more manual labor can provide a nicer reading experience for others.
audio/video; 4 minutes; 25MB; scroll down for shorter clips
Transcript
For a while now I've been trying to improve the way I program. I've made some progress. I can edit my programs live, and the tooling that enables it is not much code.
Here is the template I create new apps from. It starts out with something silly: every time I click with my mouse it draws a random rectangle.
There's not much right now, but it grows from here and in principle the app continues running as it evolves.
But debugging is still hard. It takes a long time to streamline my thinking about each new problem. I often print information to the terminal, and then struggle to visualize the text my program is printing. And if I draw debug information on the canvas, it competes for space with the app.
So I think I need new infrastructure. There are probably tools I could use that are too hard to build while deep in something else. One such tool is a windowing system. As my app runs it can dump things to other windows, and I can show them separately from my app.
Here's a window where it just prints text like I would otherwise send to the terminal.
Here's a window that plots what I draw to a 2D surface very like the app, except I can add instruments like these axes and dimensions.
180KB
The metaphor for the space is also different. My actions can have different meanings. Where the app uses mouse clicks to add new rectangles, here I can pan around.
Here's another view. This time I have some splits and multiple windows in them.
240KB
Each of these windows is a log I can scroll around in. But the stuff in the log is graphical. This one shows each rectangle drawn separately. This one focuses on just their positions, this one on just their dimensions. This one shows just widths, and this one just heights. All these windows have the same metaphor, and actions have similar meanings. But the data in them is different.
Finally, here's yet another debug view of this app. This time it's showing the sequence of actions in time rather than space, looping back when it reaches the end. I can also adjust the replay speed.
90KB
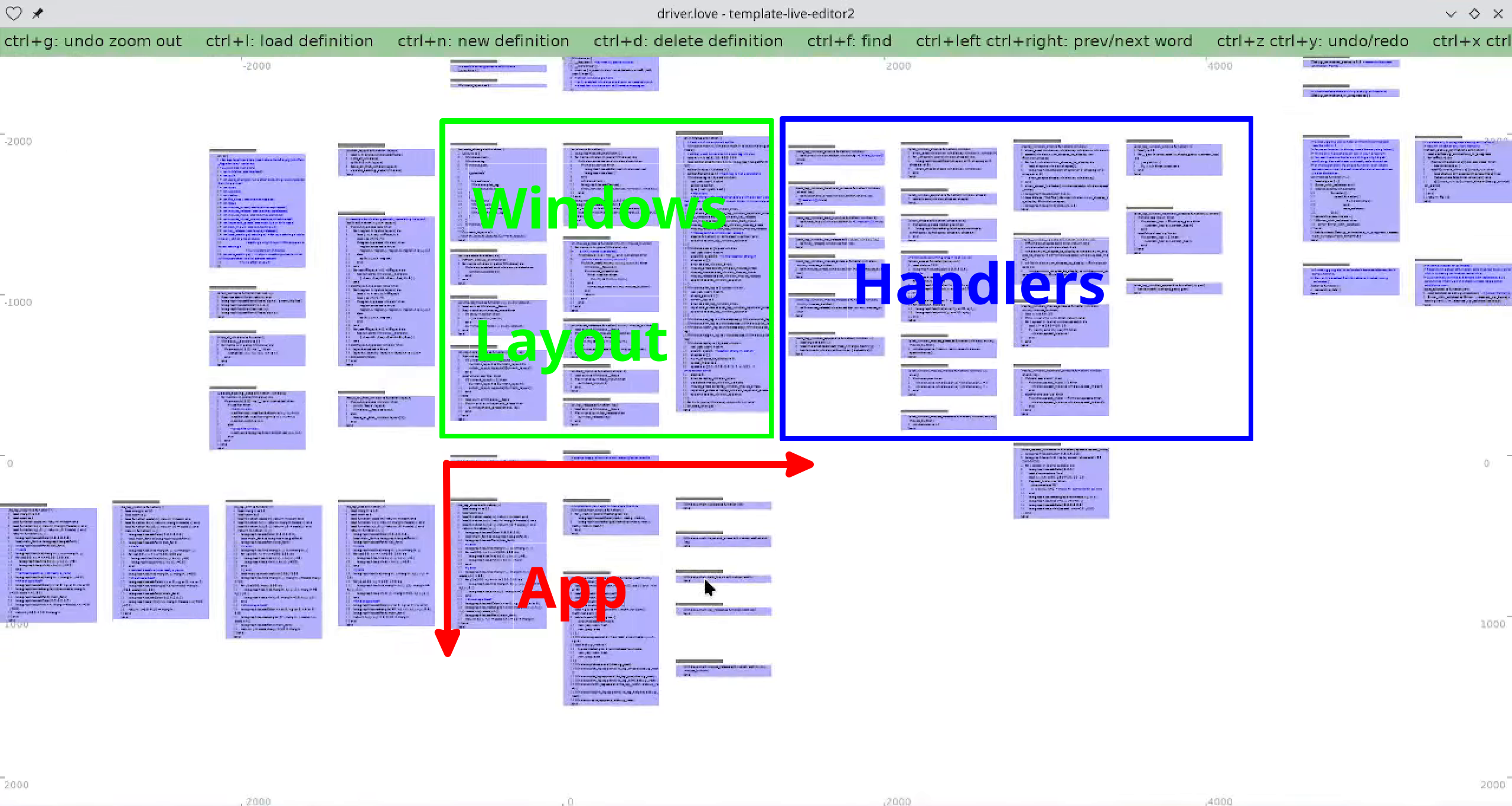
The code for this windowing system lives with my app, and this is all there is. I have some event handlers to choose from over here, and I can compose them together to create windows here. Then I compose layouts from the windows here. My app will grow downward and to the right, and lower level infrastructure will be easy to ignore above and to the left.
Hopefully this infrastructure will be helpful the next time I dig myself into a hole. It's easier now to create new places to draw debug information.
Decker. I'd for some reason assumed it was some npm and/or wasm monstrosity, but it turns out it's nice zero-dependency Javascript in a single html file that you can save and run offline! And that's in addition to the native version that uses SDL just like LÖVE. So in some ways Decker has a better cross-platform story than LÖVE, which is non-trivial to run on iOS. The downside: on a web browser on Android it's even less efficient to run than LÖVE's native app.
Rust. I spent some time playing around with a LÖVE-inspired game engine called ggez, and the much more basic wgpu crate. The promise here: Rust seems to be evolving some pretty nice cross-platform tooling, so in time we may end up with a world where it's easy to cross-compile to any platform. Of course, the compile step is not ideal, but it promises to yield much more efficient binaries that might run on lower-end devices like old phones. The eco-system is not quite there, and the npm-like dependency explosions are rough. But I want to try to look outside my comfort zone. It's possible the way forward isn't unique-snowflake minority platforms like LÖVE or Decker, but just to use a majority platform with better taste, taking the time to understand and curate the landscape of dependencies.
Anyways, here's a little program I made to try to stretch Decker to more of the sort of procedural graphics I tend to gravitate towards on LÖVE:
This is dancing letters, a fixed piece of text except we're constantly switching the case of each letter at random.
Here's the code, to give you a flavor for what Decker's quite elegant mix of Lua and APL looks like:
local s: "abcdef" # put in whatever text you want
on view do
if ! 5%sys.frame
me.clear[]
local y:each c in s random["%u","%l"] format c end
local margin:15
me.text[y margin,margin,me.size-margin*2]
end
end
And here's that code along with the surrounding card (you need a canvas widget to be present just so) in a less readable form that you can copy and paste into a deck of your own:
%%CRD0{"c":{"name":"home","script":"on view do\n \nend","widgets":{"canvas":{"type":"canvas","size":[300,200],"pos":[48,51],"animated":1,"volatile":1,"script":"local s: \"Call me Ishmael. Some years ago--never mind how long precisely--having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world. It is a way I have of driving off the spleen and regulating the circulation. Whenever I find myself growing grim about the mouth; whenever it is a damp, drizzly November in my soul; whenever I find myself involuntarily pausing before coffin warehouses, and bringing up the rear of every funeral I meet; and especially whenever my hypos get such an upper hand of me, that it requires a strong moral principle to prevent me from deliberately stepping into the street, and methodically knocking people's hats off--then, I account it high time to get to sea as soon as I can.\"\n\non view do\n if ! 5%sys.frame\n me.clear[]\n local y:each c in s random[\"%u\",\"%l\"] format c end\n local margin:15\n me.text[y (margin,margin,me.size-margin*2)]\n end\nend","border":1,"scale":1}}},"d":{}}
After a conversation with Jack Rusher and others about Emacs Nature [1, 2] and playing with Seymour by Alessandro Warth, I'm getting interested in building..
An environment for visualizing programs
(Not to be confused with visual programs, or visualization more generally.)
Start with a tiling window manager for managing named graphical canvas "buffers", using Emacs operations like split and resize.
Each buffer exposes a coordinate space of its choosing, listens for messages and positions objects in the space in response to messages.
Buffers can send messages to other buffers.
Examples of coordinate spaces:
Graphical game engines use the obvious 2D/3D cartesian systems. You position stuff using (x, y) or (x, y, z). You could also imagine polar or other coordinate systems that are studied in geometry.
The HTML DOM is a space where positions can be specified using CSS selectors or XSLT.
You can imagine a text editor operating in a coordinate space as well. Emacs seems to use a 1D coordinate, just character count from start of buffer. My stuff so far uses 2D: (line index, UTF-8 codepoint index within line)
Some examples of messages, to show the sorts of use cases this framework might unlock:
In a text editor, the cursor tracks a position, and keyboard and mouse send messages to move the cursor or insert objects (characters or longer text) at the cursor.
You can imagine print statements as a message from the "code" coordinate space to a different, 0-D (append-only so there's no notion of coordinate) space.
Terminal buffers in Emacs take the mostly 0D space of a terminal and augment it with a cursor. When you scroll up to an earlier command and hit a hotkey, the buffer sends a message to itself with the text around the cursor. The message is received at the bottom of the buffer.
Emacs Slime and other IDEs support keyboard shortcuts to send text from the current buffer to a REPL in some other buffer.
Ronin and Sketch-n-Sketch support bidirectional messages between two spaces with very different coordinate systems.
Live programming systems often show the results of a statement to its right. Examples: alv by S-ol Bekic, Bret Victor (of course), Seymour as above. These too can be seen as a reflexive message from a space to itself. In addition, the message contains an implicit coordinate: the current line.
Glamorous Toolkit, Lisp Machines and other Smalltalk systems do a lot of stuff like this. I think all of this can be cast in terms of buffers, coordinate spaces and messages, though you can imagine them as a single, very complex coordinate space like the HTML DOM, or many simple spaces with different possible coordinate systems. For example, in any of them you can create a new "log" space that you can append graphical objects to. Maybe even self-contained interactive graphical widgets.
The major question for me now is: how do you configure a buffer? You need some concise way to specify the space (perhaps just by naming from a small menu of options), handlers that listen for messages (e.g. keypress or mousepress), handlers for sending messages (e.g. widgets on the space that perform tasks when you interact with them), and generic handlers for sending messages to other buffers (e.g. print; here I'm imagining it to send a message from some arbitrary process, through say a socket, back into the environment, with enough information to route it to the appropriate buffer accompanied by a reasonable coordinate)
I have gotten annoyed by timezone calculations for hopefully the final time. Here's a static html page you can download and save locally to roughly compare times in different timezones (just hours; you're on your own for minutes).
If you're not in a whole-number timezone (Hello India), you'll need to do some additional mental arithmetic by comparing nearby rows.
That's it. Since it's almost entirely static, you can always be sure that you're seeing the same thing on this page as anyone else.
Unfortunately you need to know if you're in daylight savings time or not, something that is often beyond me. I'm not sure what to do about that without reintroducing dynamism that takes the current computer's time into account. Then I again end up wondering if others are seeing what I'm seeing.
There are a few abbreviations for America, Europe and Australia in both pages. You can see *ST and *DT on either page, which might help if you're not observing daylight time yet, but someone else is. There's a tension here between trying not to be overwhelming and emphasizing the Western or Northern hemisphere. My thinking is to only add codes for longitudes with lots of cities or with daylight savings time. Hopefully people in Bhutan or Nigeria or the Chatham Islands won't hold it against me.
I've been getting back into teaching kids programming 1:1. Of course, this time using Lua, LÖVE and Carousel. After a couple of months, it occurred to me to collect all my little impromptu puzzles and exercises into a single app anyone can go through on their own schedule.
Carousel Cards (LÖVE app, really just a zip file containing source code, 169KB)
Nowhere near done yet. But it has 50 112 little "levels", each taking between a few seconds and a minute. A full game/curriculum might need 2000 levels or something.
Emacs-style ranges on a text buffer that I can now hang attributes like color, decorations and click handlers on to.
Inserting/deleting text before a range moves it.
Inserting/deleting text after a range leaves it unchanged.
Inserting/deleting text within a range grows/shrinks it.
Deleting text at a boundary shrinks the range, and deletes it when it becomes empty.
Inserting text at boundaries can't disambiguate whether I want the text within or outside the boundaries. But I can grab some handles on the range to adjust.
The final complexity cost was 200 lines but it was a non-linear path getting there. I started out with the notion of pivots from my doodle app. There, pivots live inside the data structure for a single line of text. Since ranges now need two pivots that could be on different lines, I had to move them out. I started tracking pivots in a separate data structure, maintaining bidirectional mappings between pivots and their locations, and then tracking ranges as combinations of pivots. This quickly blew up the implementation to 500 lines, and I was juggling 27 manual tests of which half were failing.
The next day I started from scratch and threw out the notion of pivots entirely. Now I just maintain 2 locations directly inside each range, and linearly scan through them all for any book-keeping. The implementation dropped to 200 lines and the tests passed fairly quickly.
Earlier this year I threw out an implementation after suffering with it for 2+ years. It feels like I'm getting the hang of this programming thing that I threw out an implementation now after just 2 days. I'm setting a higher bar for elegance. At the same time, it's interesting that my instinct remains as poor as ever for the right approach in even a slightly new problem. Here I spent a lot of time trying to squeeze my ranges into lines so that deleting a line would transparently delete ranges within it. But I blindly assumed a fully normalized design with a first-class notion of a pivot must be a good idea.
My notebook app does simple variants of 2 and 3, and replaces 1 with explicit in-document markup.
Now I'm playing with another approach to 1. I already have the idea of pivots from my doodle app. Putting two of those pivots together should yield a range that adjusts in intuitive ways in the presence of edits. An example may be a WYSIWYG UI for adding a hyperlink to some text:
Inserting/deleting text before a range moves it.
Inserting/deleting text after a range leaves it unchanged.
Inserting/deleting text within a range grows/shrinks it.
Deleting text at a boundary shrinks the range, and only deletes the attached attributes if the range becomes empty. This makes ranges more robust to deletion than my doodles which attached to a single pivot.
Inserting text at boundaries can't always do what you want. I imagine it'd be nice to have handles that you can drag to adjust a range.